没关系,本文就试图以最简单的语言,给你普及一下我们通常所说的人工智能的四种方法,并通过有趣的例子,帮你建立一些直观的感受,而且很容易读懂,是一篇机器学习入门的不可多得的好文章。
同时,本文还包括相关的很多文章和论文,是个很不错的资源包。请在后台回复关键词“清华大数据”,获得本文涉及的论文资源包。
好了,5分钟时间,轻松学习到底什么是监督学习,无监督学习,半监督学习,以及强化学习,enjoy!
根据训练方法的不同,机器学习可以分为四类:
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
本文会对各种学习方法给出一种非常直观的解释。
文中,我们也会为你介绍那些经常在论文中出现的名词术语,还会给出不同的机器学习方法所对应的学习资源。
总的来说,本文的分类方法,既适用于传统的机器学习,又适用于新出现的深度学习。
对于数学相关的问题,可以看看斯坦福大学的深度学习教程,它涵盖了监督学习和无监督学习,且附有代码实例。
斯坦福大学的深度学习教程(吴恩达等人撰写)
http://ufldl.stanford.edu/tutorial/
1. 监督学习
监督学习是用正确答案已知的例子来训练神经网络,也就是用标记过的数据。如果我们想设计一个系统——从相册中找出包含你的父母的照片,基本的步骤如下:
第一步:数据的生成和分类
首先,需要将你所有的照片看一遍,记录下来哪些照片上有你的父母。然后把照片分为两组。第一组叫做训练集,用来训练神经网络。第二组叫做验证集,用来检验训练好的神经网络能否认出你的父母,正确率有多少。
之后,这些数据会作为神经网络的输入,得到一些输出。用数学语言表示就是:找到一个函数,该函数的输入是一幅照片。当照片上有你的父母的时候,输出为1;没有的时候,输出为0。
这种问题通常叫做分类。因为这个例子中,输出只有两个可能,是或者不是。
当然,监督学习的输出也可以是任意值,而不仅仅是0或者1。举另一个例子,我们的神经网络可以预测一个人还信用卡的概率。这个概率可以是0到100的任意一个数字。这种问题通常叫做回归。
第二步:训练
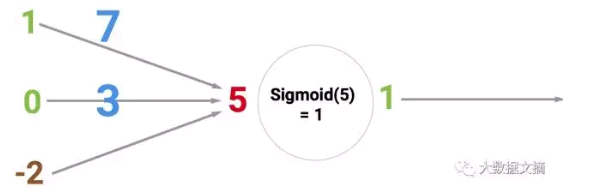
在进行训练这一步时,每一幅图像都会作为神经网络的输入,根据一定的规则(激活函数),决定某个神经元的输出,进而得到某一层的输出。当计算完所有神经元的时候,最后得到了最右边的神经元(输出节点)的输出,是0还是1。
上一步中,我们已对照片上是否有你父母做过标记。这样,我们就能知道神经网络所预测的结果是否正确,并把这一信息反馈回神经网络。
这里所反馈的,是成本函数的计算结果,即神经网络计算结果与实际情况的偏差。这个函数也叫做目标函数、效用函数或者适应度函数。这一结果用来调整神经元的权重和偏差,这就是BP算法,即反向传播算法,因为该信息是从后向前传递的。
刚才针对的是一张照片。你需要对每张照片不断重复这个过程。每个过程中都要最小化成本函数。
BP算法有很多实现方法,最常用还是梯度递减的方法。
Algobeans 非常通俗易懂的解释了这个方法。Michael Nielsen 在此基础上,加上了积分和线性代数,也给出了形象生动的演示。
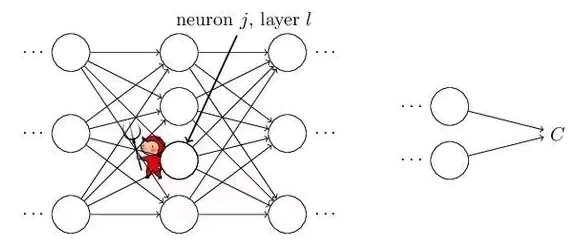
神经网络入门
https://algobeans.com/2016/11/03/artificial-neural-networks-intro2/
反向传播算法原理
http://neuralnetworksanddeeplearning.com/chap2.html
第三步:验证
至此,第一组中的数据已经全部用完。接下来我们会用第二组数据验证训练得到的模型的准确率。
优化模型的许多参数(超参)需要优化,因此导致第二步和第三步通常会交叉进行。常用的超参有神经网络有多少个神经元,有多少层神经元,哪个函数用来激活一个神经元(激活函数),用多快的速度来训练网络(学习速率)等等。Quora 工程师主管的这一回复很好的解释了这些超参。
Quora 工程师主管回复
https://www.quora.com/What-are-hyperparameters-in-machine-learning
第四步:应用
完成以上三步,模型就训练好了。接下来,我们可以把模型融合到程序中。模型可以提供一个 API,例如 ParentsInPicture(photo)。当应用程序调用该 API 的时候,模型会计算得到结果,并返回给应用程序。
稍后,我们将用同样的方法步骤,在 iPhone 上制作一个 APP,用来识别名片。
对数据集进行标记的成本是非常高的。因此,必须确保使用网络得到的收益比标记数据和训练模型的消耗要更高。
举例来说,在医学领域,根据X光照片标记病人是否患有癌症成本是很高的,但能以极高的准确率来诊断病人是否患癌的系统则又非常有价值。
2. 无监督学习
无监督学习 中使用的数据是没有标记过的,即不知道输入数据对应的输出结果是什么。无监督学习只能默默的读取数据,自己寻找数据的模型和规律,比如聚类(把相似数据归为一组)和异常检测(寻找异常)。
假设你要生产T恤,却不知道 XS、S、M、L 和 XL 的尺寸到底应该设计多大。你可以根据人们的体测数据,用聚类算法把人们分到不同的组,从而决定尺码的大小。
假如你是初创的安全相关公司的 CTO。你想从网络连接情况找到一些蛛丝马迹:突然增大的数据流量可能意味着有快要离职的员工下载所有的 CRM 历史数据,或者有人往新开账户里面转了一大笔钱。如果你对这类事情感兴趣,可以参考无监督异常检测算法概览:
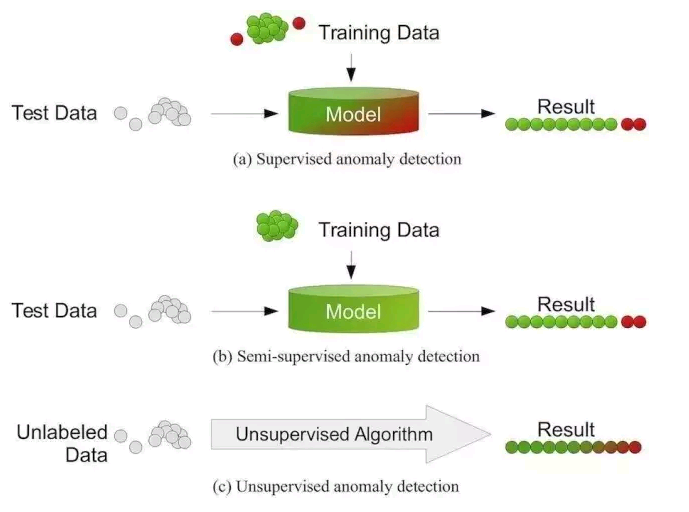
无监督学习概览
http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0152173
Google Brain 团队的人想让系统知道 YouTube 视频里面有什么。他们所实现的 “YouTube 找猫算法”重新激起了大众对于人工智能的热情。他们的论文介绍了 Google Brain 同斯坦福大学的 Quoc Le 和吴恩达合作,开发出一个分类算法,能够把 YouTube 视频分为很多不同的类,其中一类就是猫。他们并没有为系统设置“找猫”的任务,也没有提供任何标记数据,但是算法能对 YouTube 视频自动分组,并且找出了猫,当然还找出了ImageNet 所定义的22000个类别中的数千个其他物体。
吴恩达“从 YouTube 视频中找猫”的论文
https://arxiv.org/abs/1112.6209
更多的无监督学习技术可以从以下文献找到:
自编码机(Autoencoding)
http://ufldl.stanford.edu/tutorial/unsupervised/Autoencoders/
主成分分析(PCA)
https://www.quora.com/What-is-an-intuitive-explanation-for-PCA
随机森林(Random forests)
https://en.wikipedia.org/wiki/Random_forest
K均值聚类(K-means clustering)
https://www.youtube.com/watch?v=RD0nNK51Fp8
https://www.udacity.com/course/machine-learning-unsupervised-learning–ud741
最有前景的无监督学习方法之一,是刚刚出现的生成式对抗网络。该方法由当时还在 Yoshua Bengio 实验室工作的 Ian Goodfellow 提出。在该模型中有两个相互对抗的神经网络组成。一个叫做生成器,负责生成真实数据的近似,企图骗过另一个叫做判别器的网络。这个方法已经取得了优异的成果,比如从文本描述或者手绘素描中生成图片,所生成的图片跟照片一样逼真。
Yann LeCun谈GAN
https://www.quora.com/What-are-some-recent-and-potentially-upcoming-breakthroughs-in-deep-learning
从文本描述生成图片的论文
https://arxiv.org/abs/1612.03242
从手绘素描生成图片的论文
https://arxiv.org/abs/1611.07004v1
3. 半监督学习
半监督学习训练中使用的数据,只有一小部分是标记过的,而大部分是没有标记的。因此和监督学习相比,半监督学习的成本较低,但是又能达到较高的准确度。举例来说,我们在 AI 咨询公司 Joostware 工作的朋友 Delip Rao,用半监督学习方法对每类只标记30个数据,和用监督学习对每个类标记1360个数据,取得了一样的效果。并且这使得他们的客户可以标记更多的类,从20个类迅速扩展到了110个类。
一个直观的解释为什么无标记也能提高准确率:即使不知道正确的答案,但是可以知道输入数据长什么样,有什么可能的取值。
喜欢数学的可以读读朱晓进教授长达135页的教程和他2008年那篇半监督学习纵览。
半监督学习教程
http://pages.cs.wisc.edu/~jerryzhu/pub/sslicml07.pdf
半监督学习纵览
http://pages.cs.wisc.edu/~jerryzhu/pub/ssl_survey.pdf
4. 强化学习
强化学习也是使用未标记的数据,但是可以通过某种方法知道你是离正确答案越来越近还是越来越远(即奖惩函数)。传统的“冷热游戏”(hotter or colder,是美版捉迷藏游戏 Huckle Buckle Beanstalk 的一个变种)很生动的解释了这个概念。你的朋友会事先藏好一个东西,当你离这个东西越来越近的时候,你朋友就说热,越来越远的时候,你朋友会说冷。冷或者热就是一个奖惩函数。半监督学习算法就是最大化奖惩函数。可以把奖惩函数想象成正确答案的一个延迟的、稀疏的形式。
在监督学习中,能直接得到每个输入的对应的输出。强化学习中,训练一段时间后,你才能得到一个延迟的反馈,并且只有一点提示说明你是离答案越来越远还是越来越近。
DeepMind 在自然杂志上发表了一篇论文 ,介绍了他们把强化学习和深度学习结合起来,让神经网络学着玩各种雅达利(Atari)游戏(就是各种街机游戏),一些游戏如打砖块(breakout)非常成功,但是另一些游戏比如蒙特祖玛的复仇,就表现的很糟糕。
DeepMind 强化学习论文(https://deepmind.com/blog/deep-reinforcement-learning/ Nervana),团队(已被英特尔收购)的博客有两篇文章非常棒,把强化学习的技术细节讲解清楚了。
Nervana 强化学习博文:
I – https://www.nervanasys.com/demystifying-deep-reinforcement-learning/
II – https://www.nervanasys.com/deep-reinforcement-learning-with-neon/
斯坦福大学的学生 Russell Kaplan、Christopher Sauer 和 Alexander Sosa 论述了强化学习的存在的问题,并给出了很聪明的解决方案。
DeepMind 的论文介绍了没有成功利用强化学习玩蒙特祖玛的复仇。按照三个人的说法是因为强化学习只能给出很少的提示,即稀疏的延迟。如果没有足够多的“冷热”的提示,很难找到被藏起来的钥匙。斯坦福的学生们通过让系统理解和执行自然语言的提示,比如“爬楼梯”,“拿钥匙”等,在 OpenAI 大赛中获得了冠军,其视频如下:
关于强化学习的书
http://incompleteideas.net/sutton/book/the-book-1st.html



评论0