前言
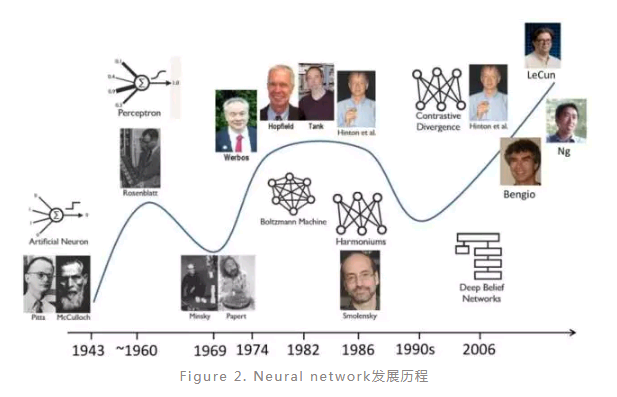
深度学习(deep learning)的概念最早可以追溯到1940-1960年间的控制论(cybernetics),之后在1980-1990年间发展为连接主义(connectionism),第三次发展浪潮便是2006年由人工神经网络(Artificial neural network)扩展开来并发展成为今天十分火热的深度学习(Figure 2)。实际上,深度学习的兴起和发展是非常自然的,人们在应用经典的机器学习方法时,需要对具体的问题或者数据相当地了解并从中人工地提取特征才能很好的解决问题,然而人工提取特征是非常复杂耗时的。因此,能够自动从数据中学习特征的方法就具有非常大的发展潜力,这类方法也就是一类被称为表征学习(Representation learning)的方法。
紧接着,研究者们发现,深层次的表征学习模型可以从简单的特征中抽象出更为复杂的特征并且更有利于最终的分类判别,由此便发展出了深度学习框架。当然,深度学习的发展也离不开BP等算法、计算硬件、数据规模等的发展。深度学习可以理解成是机器学习的一种框架,与经典的浅层学习(Shallow learning)如SVM,LR等相对应,可以认为是机器学习发展的第二大阶段。目前,深度学习在人工智能领域发挥着非常重要的作用,甚至可以说人工智能的发展正是得益于深度学习的发展,由于它们之间有着密不可分的关系,非专业人士常常会将深度学习、人工智能、表示学习、机器学习等概念混为一谈。
另外,最近几年,由于人工智能、互联网等火速发展,它们背后的技术也备受学术界和业界人员的推崇,其中深度学习由于其强大的威力以及较低的门槛而受到最多的关注。本文致力于从模型、技术、优化方法、常用框架平台、应用、实例等多个方面来向读者介绍深度学习,阐述深度学习到底有哪些威力,并且文末会给读者推荐一些深度学习的学习资源。
深度学习是什么?
如前言所述,深度学习是机器学习的一种框架,是人工智能的基础技术之一,其与人工智能、表示学习以及机器学习的关系由Figure 3可见,即机器学习是实现人工智能的一种方法,而表示学习又是一种机器学习的框架,深度学习包含在表示学习中。
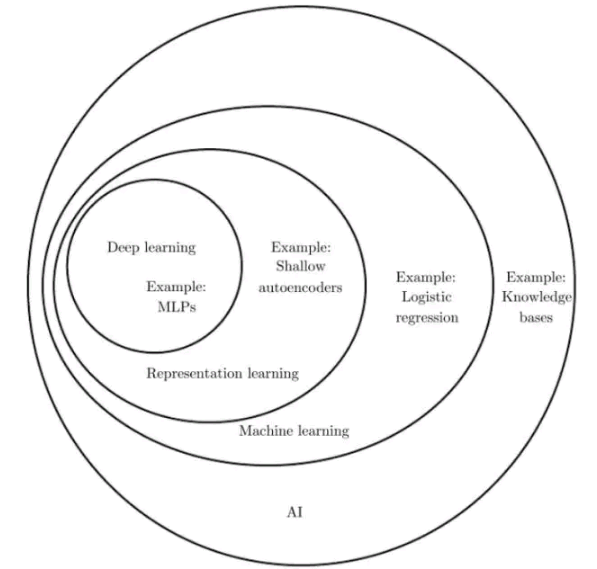
Figure 3. Deep learning定位(图片来源:Ian Goodfellow et al. Deep learning.)
深度学习模型可以自动从输入数据中学习特征并用于训练,模型的浅层结构提取简单的特征,深层结构则基于浅层结构获取的特征提取更为抽象的特征,这是深度学习区别于传统机器学习以及普通表征学习模型的学习方式。Figure 4展示了不同机器学习方法的学习方式。
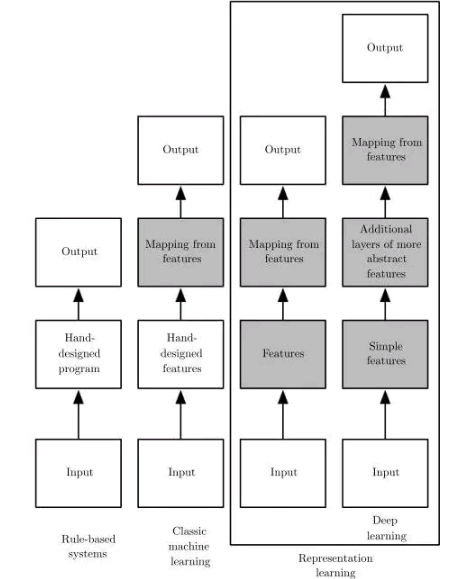
Figure 4. Deep learning特征学习过程(图片来源:Ian Goodfellow et al. Deep learning.)
那么,深度学习的深度到底体现在什么方面呢?对于这个问题,目前主要有两种观点:第一种观点认为,深度学习的深度是由于计算图的长度决定的,也就是模型将输入映射到输出的过程中,计算的路径长度。对于该观点,如何定义计算单元至关重要,而目前又没有统一的关于计算单元的定义;第二种观点则认为深度学习的深度是由描述输入到输出之间概念关系图的深度决定的,也就是所定义模型的结构深度,然而这种结构上的深度往往与计算的深度不一致。以上两种观点提供了两种理解深度学习的角度,我们既可以将其理解为模型结构的深度也可以理解为计算的深度,笔者认为这对于理解深度学习的本质并无影响。
常见模型
前面多次提到深度学习是一种机器学习框架,那么该框架下的具体的模型有哪些呢?下面为大家介绍几种常见的深度学习模型。
MLP:
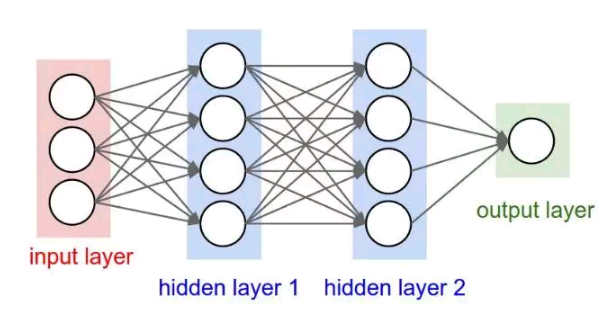
MLP (Multilayer perceptron)是一个典型的深度学习模型,也叫前向深度网络(Feedforward deep network),主要由多层神经元构成的神经网络组成(Figure 5),包括输入层、中间层和输出层,层与层之间是全连接的,除了输入层,其他层每个神经元包含一个激活函数,因此,MLP可以看成是一个将输入映射到输出的函数,这个函数包括多层乘积运算和激活运算。MLP通过前向传播计算最终的损失函数值,再通过反向传播算法(BP)计算梯度,利用梯度下降来对模型参数进行优化。MLP的出现解决了感知器无法学习XOR函数的问题,使得人们对神经网络重拾信心。
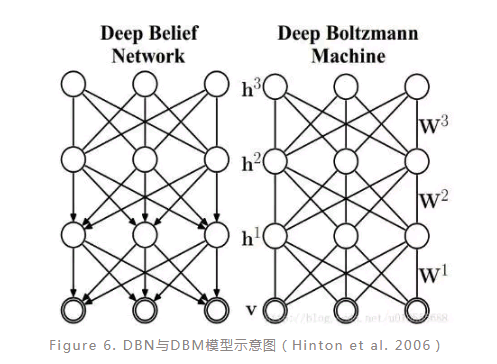
DBN与DBM:
DBN(Deep belief network)也是一种比较经典的较早提出的深度学习模型。DBN是基于RBM(Restricted Boltzmann Machine)模型建立的,更具体地,DBN模型可以看成是由多个RBM结构和一个BP层组成的,其训练过程也是从前到后逐步训练每一个RBM结构,使得每一个RBM的隐层达到最优,从而最优化整体网络。值得注意的是,在DBN的结构中,只有最后两层之间是无向连接的,其余层之间均具有方向性,这是DBN区别与后面DBM的一个重要特征。
DBM(Deep Boltzmann machine)模型也是一种基于RBM的深度模型,其与RBM的区别就在于它有多个隐层(RBM只有一个隐层)。DBM的训练方式也是将整个网络结构看成多个RBM,然后从前到后逐个训练每个RBM,从而优化整体模型。在DBM模型中,所有相邻层之间的连接是无向的。DBN与DBM模型中层间节点之间均无连接,且节点之间相互独立。
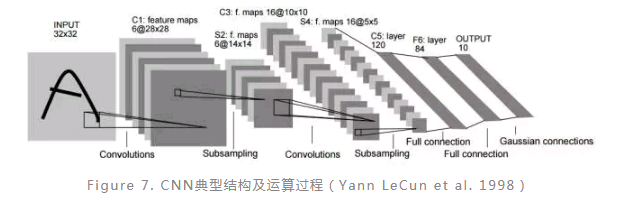
CNN:
CNN(convolutional neural network)是一种前向人工神经网络模型,由Yann LeCun等人在1998年正式提出,其典型的网络结构包括卷积层、池化层和全连接层。下图(Figure 7)所示就是一种典型的CNN结构(LeNet-5),给定一张图片(一个训练样本)作为输入,通过多个卷积算子分别依次扫描输入图片,扫描结果经过激活函数激活得到特征图,然后再利用池化算子对特征图进行下采样,输出结果作为下一层的输入,经过所有的卷积和池化层之后,再利用全连接的神经网络进行进一步的运算,最终结果经输出层输出。
CNN模型强调的是中间的卷积过程,该过程通过权值共享大幅度降低了模型的参数数量,使得模型在不失威力条件下可以更为高效地得到训练。CNN模型是非常灵活的,其结构可以在合理的条件下任意设计,比如可以在多个卷积层之后加上池化层,正是由于这种灵活性,CNN被广泛地应用在各种任务中并且效果非常显著,比如后面将要介绍的AlexNet、GoogLeNet、VGGNet以及ResNet等。
当然,这种灵活性使得CNN的结构本身也成为了一种超参,这就难以保证针对特定任务所采用的模型是否是最优模型。在现实的应用中,CNN更多的用于处理一些网格数据,例如图片,对于这类数据CNN的卷积过程能发挥的作用相对更大。当然,CNN是可以完成多种类型的任务的,包括图片识别、自然语言处理、视频分析、药物挖掘以及游戏等。
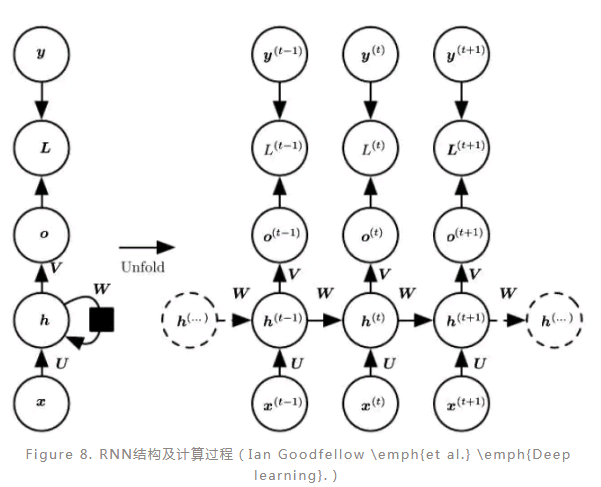
RNN:
RNN(Recurrent neural network)是一类用于处理序列数据的神经网络模型。典型的RNN模型通常是由三类神经元组成,分别是输入、隐藏和输出,其中输入单元只与隐藏单元相连,隐藏单元则与输出、上一个隐藏单元以及下一个隐藏单元相连,输出单元只接受隐藏单元的输入。在RNN训练过程中,一般需要学习优化三种类参数,即输入映射到隐层的权重、隐层单元之间转换权重以及隐层映射到输出的权重。
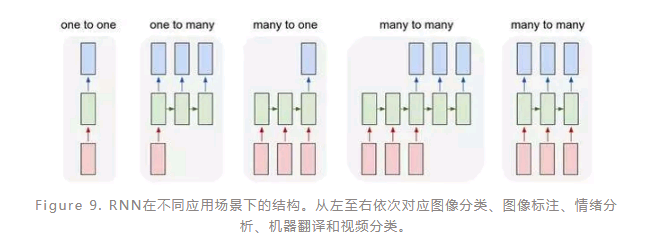
如图(Figure 8)是典型的RNN结构以及计算过程。在RNN的计算过程中,序列数据前面部分的信息通过隐藏单元传递到后面的部分,因此在后面部分的计算过程中,前面部分的信息也考虑进来,这就模拟了序列不同部分之间的依赖关系。显然,RNN模型更适用于序列性的数据,尤其是上下文相关的序列,这使得RNN在情感分析、图像标注、机器翻译等方面应用十分广泛。值得注意的是在不同的任务中,RNN的结构有所差异,比如在图像标注的场景中RNN是一对多的结构,而在情感分析的场景中则是多对一的结构(Figure 9)。
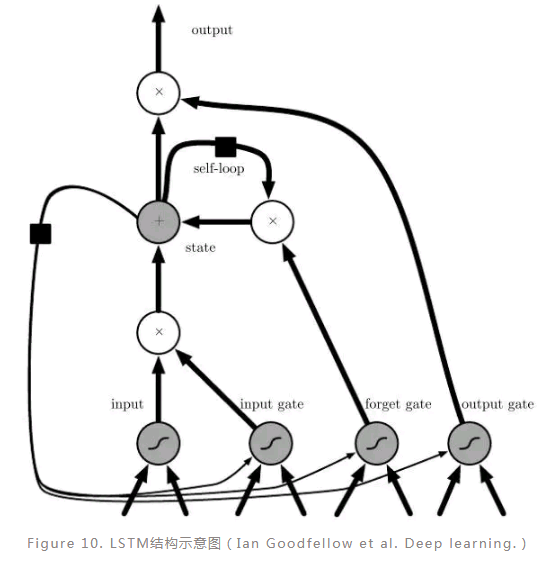
LSTM:
LSTM(Long short-term memory)模型本质上也是一种RNN模型,它与RNN的区别在于它引入了元胞状态(Cell state)的概念,并且可以通过门(gate)来向元胞状态加入或者删除信息,另外,LSTM还可以通过门构成封闭的回路(Figure 10),这使得LSTM得以克服RNN无法有效记忆长程信息的弱点。如图(Figure 10)是一种常见的LSTM单元,其中包含输入、输入门、遗忘门、状态、输出门、输出等组成单元。
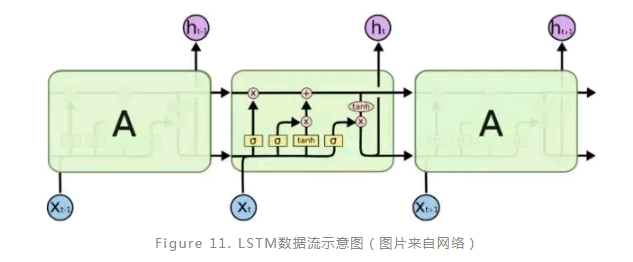
在LSTM模型中所谓的门其实就是一个函数运算,例如输入门可以是所有输入经过权重乘积运算之后的sigmoid函数运算。对于一个序列型数据样本,当前输入节点会综合上一个节点的隐层输出信息,分别通过多个不同门运算之后输出作为当前节点的隐层输出信息,并且同时与上一个节点的元胞状态信息进行综合输出作为当前节点的元胞状态信息输出(Figure 11)。LSTM既然是一种特殊的RNN 模型,那么很多可以应用RNN的场景LSTM也适用,例如情感分析、图像标注等等。当然,LSTM也具有非常多的变种,它们在不同的任务中表现不同,这也需要应用的时候有一些了解。
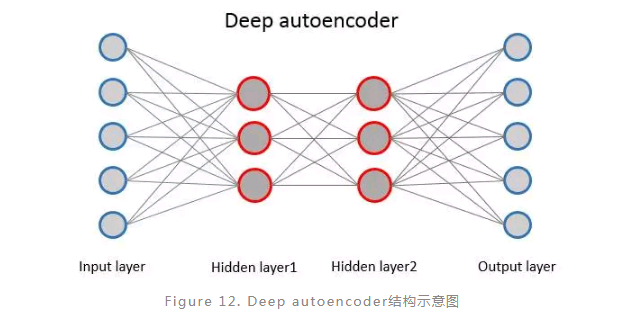
Deep autoencoder:
Autoencoder是一种神经网络,其输入层与输出层表示相同的含义并且具有相同数量的神经元。Autoencoder的学习过程就是将输入编码然后再解码重构输入作为输出的过程,将输入编码生成的中间表示的作用类似于对输入进行降维,因此autoencoder常常用于特征提取、去噪等。
普通的autoencoder一般是指中间只有一层隐层的网络模型,而deep autoencoder则是中间有多层隐层的网络模型。Deep autoencoder的训练与DBM训练类似,每两层之间利用RBM进行预训练,最终通过BP来调整参数。同样地,deep autoencoder也有非常多的变种(例如sparse autoencoder,denoise autoencoder等),分别对应于不同的任务。
深度网络的优化方法
前面例举了一些深度学习比较常见的一些模型,那么这些模型都是如何进行优化的呢?本节将介绍一些比较常用的深度网络优化的方法。
SGD:
SGD(Stochastic Gradient Descent)即随机梯度下降算法,是机器学习中最常用的优化方法之一。SGD的工作原理就是梯度下降,也就是以一定的步长(learning rate)沿着参数梯度的方向调整参数,只不过在SGD中是对随机抽取的一个样本通过梯度下降更新一次参数。在实际应用SGD的时候有多个参数可以调节,主要包括学习率、权值衰减(weight decay)系数、动量以及学习率衰减系数,通过调整这几个参数,可以使得模型以较快的速率收敛且不易过拟合。SGD参数更新过程如下:

Adagrad:
Adagrad的优化过程也是基于梯度的,该优化方法可以对每一个参数逐一自适应不同的学习速率,对于比较稀疏的特征以较大的学习率更新,对于非稀疏的特征则用较小的学习率更新。这种自适应的过程是通过利用累积梯度来归一化当前学习率的方式实现的,其优化参数的过程如下:

Adadelta:
Adadelta是Adagrad方法的扩展。前面提到在Adagrad中由于累积梯度增长过快会导致学习率衰减过快,Adadelta的出现就是为了解决这一问题的。具体的实现方式是在之前的参数序列开一个窗口,只累加窗口中参数梯度,并且以平方的均值代替Adagrad中的平方和。其参数更新过程如下:

Adam:
Adam(Adaptive Moment Estimation)同样也是一种参数学习率自适应的方法,它主要是依据梯度的一阶矩和二阶矩来调整每个参数整学习率。具体的参数更新方法如下:

Adamax:
Adamax是Adam的一种变体,它在学习率的限制上做了一些改动,即利用累积梯度和前一次梯度中的最大值来对学习率进行归一化。这样的限制在计算上相对简单。
Nadam:
Nadam也是Adam的一种变体,它的变动在于它带有Nesterov动量项。一般来说,Nadam的效果会比RMSprop和Adam要好,但是在计算上比较复杂。
深度网络中常用的技术
在实际的应用中,深度学习模型在数据量不是足够大的条件下是非常容易过拟合的,因此需要通过一些技术和技巧来控制训练过程,减弱甚至防止严重的过拟合现象。那么,有哪些类似的常用的技术呢?接下来我们就介绍一些比较有用的进一步优化模型训练的技术。
BP algorithm:
BP(Backpropagation)算法其实只是一种训练神经网络模型的方法,主要是通过链式求导法则对目标函数求关于参数的导数,求导的过程从输出层一直反向传递至输出层,根据求出的导数利用前一节介绍的优化算法对参数进行更新,从而优化模型。在应用BP算法优化模型的过程中,常常会出现梯度消失、陷入局部最优以及梯度不稳定等问题,这些问题会导致模型收敛缓慢、泛化能力降低等后果。当然,这些问题的出现也与模型中选择的激活函数有一定的关系,因此合理选择激活函数会一定程度上弱化以上问题。目前,应用比较多的激活函数主要有sigmoid、tanh、ReLu、PReLu、RReLU、ELU、softmax等等,根据具体的问题选择激活函数有利于BP算法的高效执行。
Dropout:
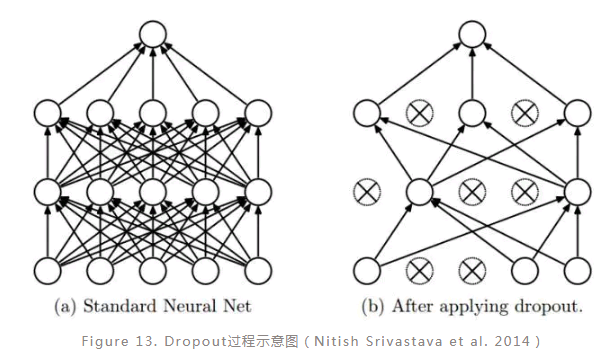
前面提到深度学习模型是非常容易过拟合的,主要的原因在于深度学习模型是非常复杂的,具有大量的参数,在样本量不是足够多的情况下是很难保证模型的泛化能力的。因此,一种防止过拟合的方法dropout被提出,dropout的主要思想是在训练的过程中随机使一些神经元失活来降低模型的复杂度,当然这个过程是并不影响BP的执行。Dropout的具体执行过程如图(Figure 13)所示,通过比较相同的网络在使用dropout前后的分类效果,发现在MNIST、CIFAR-10、CIFAR-100、ImageNet、TIMIT等数据集上使用dropout的预测效果更好。
Batch Normalization:
深度学习网络在训练的过程中有一个很大问题是数据流经每层时分布会随着参数的变化而发生变化,也就是常说的内部协变量漂移现象(internal covariate shif),这种现象会导致模型的训练非常缓慢,并且对参数的初始化有较高的要求。Batch Normalization的出现则很大程度上解决了这一问题,其作用的原理是直接在每层的输入上加上一层归一化层,先对输入进行归一化再传递至激活函数。经过Batch Normalization处理之后,就可以使用较大的学习率从而加快训练速度,并且降低初始化的要求。加入Batch Normalization来训练深度网络的过程如图(Figure 14)。Sergey Ioffe et al.通过实验发现加入Batch Normalization的网络在ImageNet数据集上表现更好。

Figure 14. 加入Batch Normalization的网络的训练过程(Sergey Ioffe et al. 2015)
Early stopping:
Early stopping也是一项在实际应用深度学习模型时防止过拟合的技术,该技术主要通过控制训练的轮数(epoch)来防止过拟合,也就是在validation loss不再持续下降时自动停止训练。实际上,early stopping可以应用在很多机器学习问题上,例如非参回归、boosting等。另外,early stopping也可以看成是一种正则化的形式。
Regularization:
这里所说的regularization是指狭义上像L1、L2等对控制权重的正则化,不包括前面提及的Dropout和early stopping等。对网络的权重参数加上L1或L2正则项也是一种比较常用的防止过拟合的手段,L1/L2正则化的方法在机器学习中应用非常广泛,这里也不再赘述。
深度学习常见的实现平台和框架
深度学习模型由于其复杂性对机器硬件以及平台均有一定的要求,一个好的应用平台可以使得模型的训练事半功倍。那么,针对深度学习有哪些比较流行好用的平台和框架呢?下面就向大家介绍一些比较常用的深度学习平台以及它们的优缺点。
Caffe:
Caffe是由美国加州伯克利分校视觉与学习中心在2013年开发并维护的机器学习库,它对卷积神经网络具有非常好的实现(http://caffe.berkeleyvision.org )。Caffe是基于C/C++开发的,所以模型计算的速度相对较快,但是Caffe不太适合文本、序列型的数据的处理,也就是在RNN的应用方面有很大的限制,其优缺点可以简单的总结如下:
优点:适合图像处理;版本稳定,计算速度较快
缺点:不适合RNN应用;不可扩展;不便于在大型网络中使用;C/C++编程难度较大,不够简洁;几乎不再更新
Theano/Tensorflow:
Theano和Tensorflow都是比较底层的机器学习库,并且都是一种符号计算框架,它们都适用于基于卷积神经网络、循环神经网络以及贝叶斯网络的应用,它们都提供Python接口,Tensorflow还提供C++接口。Theano是在2008年由蒙特利尔理工学院LISA实验室开发并维护的(http://deeplearning.net/software/theano/ ),非常适合数值计算优化,并且支持自动计算函数梯度,但它不支持多GPU的应用。Tensorflow是由Google Brain团队开发的,目前已经开源,由Google Brain团队以及众多使用者们共同维护(https://www.tensorflow.org )。
Tensorflow通过预先定义好的数据流图,对张量(tensor)进行数值计算,使得神经网络模型的设计变得非常容易。与Theano相比,Tensorflow支持分布式计算和多GPU的应用。就目前来看,Tensorflow是在深度学习模型的实现上应用最为广泛的库。
Keras:
Keras是一个基于Theano和Tensorflow的,高度封装的深度学习库(https://keras.io/ )。它是由是由谷歌软件工程师Francois Chollet开发的,在开源之后由使用者共同维护。Keras具有非常直观的API,使用起来非常的简洁,一般只需要几行代码便可以构建出一个神经网络模型。目前,Keras已经发布2.0版本,支持使用者从底层自定义网络层,这很大程度上弥补了之前版本在灵活性上不够的缺陷。
Torch/PyTorch:
Torch是基于Lua语言开发的一个计算框架(http://torch.ch/ ),可以非常好的支持卷积神经网络。在Torch中网络的定义是以图层的方式进行的,这导致它不支持新类型图层的扩展,但是新图层的定义相对比较容易。Torch运行在LuaJIT上,速度比较快,但是目前Lua并不是主流编程语言。另外,值得注意的是Facebook在2017年1月公布了Torch 的Python API,即PyTorch的源代码。PyTorch支持动态计算图,方便用户对变长的输入输出进行处理,另外,基于python的库将大幅度增加Torch的集成灵活性。
Lasagne:
Lasagne是一个基于Theano计算框架(http://lasagne.readthedocs.io/en/latest/index.html ),它的封装程度不及Keras,但它提供小的接口,这也使得代码与底层的Theano/Tensorflow比较为简洁。Lasagne这种半封装的特性,平衡了使用上的便捷性和自定义的灵活性。
DL4J:
DL4J(Deeplearning4j)是一个基于Java的深度学习库(https://deeplearning4j.org/ )。它是由Skymind公司在2014年发布并开源的,其包含的深度学习库是商业级应用的开源库,由于是基于Java的,所以可以与大数据处理平台Hadoop、Spark等集成使用。DL4J依靠ND4J进行基础的线性代数运算,计算速度较快,同时它可以自动化并行,因此十分适合快速解决实际问题。
MxNet:
MxNet是一个由多种语言开发并且提供多种语言接口的深度学习库(http://mxnet.io/ )。MxNet支持的语言包括Python,R,C++,Julia,Matlab等,提供C++, Python, Julia, Matlab, JavaScript,R等接口。MxNet是一个快速灵活的学习库,由华盛顿大学的Pedro Domingos及其研究团队开发和维护。目前,MxNet已被亚马逊云服务所采用。
CNTK:
CNTK是微软的开源深度学习框架(http://cntk.ai ),是基于C++开发的,但是提供Python接口。CNTK的特点是部署简单,计算速度比较快,但是它不支持ARM架构。CNTK的学习库包括前馈DNN、卷积神经网络和循环神经网络。
Neon:
Neon是Nervana公司开发的一个基于Python的深度学习库(http://neon.nervanasys.com/docs/latest/ )。该学习库支持卷积神经网络、循环神经网络、LSTM以及Autoencoder等应用,目前也是开源状态。有报道称在某些测试中,Neon的表现要优于Caffe、Torch和Tensorflow。
深度学习网络实例
通过前面的介绍,读者对于深度学习已经有了比较详细的了解,那么实际应用中深度学习网络究竟是怎么样设计的呢?本节我们向大家介绍几种应用效果非常好的深度学习网络,从中我们可以体会到神经网络设计的一些技巧。
LeNet:
LeNet是由Yann LeCun等最早提出的一种卷积神经网络,我们在介绍CNN的时候已经提到过该网络(Figure 7)。LeNet网络总共有7层(不包括输入层),分别是C1、S2、C3、S4、C5、F6以及OUTPUT层,其中C1、C3为卷积层,S2、S4为下采样层,C5、F6为全连接层。该网络的输入时32 X 32的图片,C1包含6个特征图(feature maps),C3包含16个特征图,两个全连接层的神经元数量分别是120和84,最终的输出层含有10个神经元,对应十个类别。这个网络在训练过程中总共需要优化大约12000个参数,在手写数字识别(MNIST数据集)的任务上效果远优于传统的机器学习方法。这一网络的提出提供了一个卷积神经网络应用的范例,也就是将卷积层与采样层(后来的池化层)交替连接,最后在展开连接全连接层。实践证明在很多任务中这一网络结构具有较好的表现。
AlexNet:
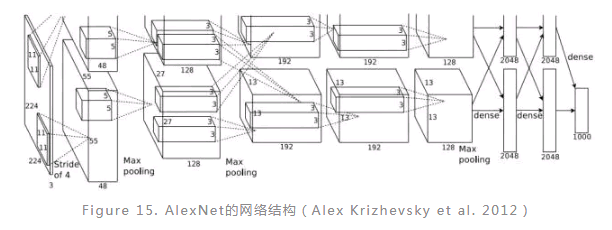
AlexNet是Alex和Hinton参加ILSVRC2012比赛时所使用的卷积神经网络,该网络可以说是更深层次的CNN在大数据集上应用的开山之作,随后诸多应用均是在此网络的基础上发展而来。AlexNet由5个卷积层和3个全连接层组成,其中第1,2,5卷积层后加入了池化过程(Figure 15),各层神经元的数目分别是253440、186624、64896、64896、43264、4096、4096和1000,总计涉及的参数达到6千万。该网络的训练集是来自ImageNet的140万包含1000个类别的高分辨率图片,其中有5万作为验证集,15万作为测试集。在训练该网络的过程中,采用ReLu作为激活函数,并且对图片数据通过水平翻转等方法进行了扩增,为了防止过拟合,该网络中还使用了dropout技术,网络的优化采用了批量梯度下降并加入了动量和权值衰减。整个训练过程在两个GTX 580的GPU上持续了5-6天。最终的结果是该网络在ILSVRC2012比赛中取得了最好的成绩,并且远远由于其他方法。
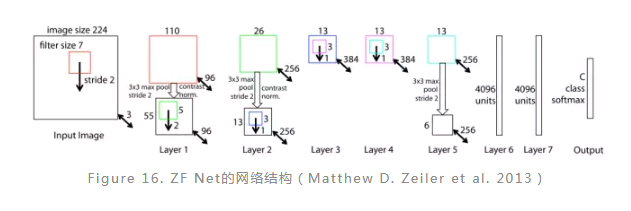
ZF Net:
ZF Net是在ILSVRC2013比赛中由Zeiler和Fergus根据AlexNet提出的网络。实际上,该网络只是对AlexNet做了一些修改和调整,因此二者之间的网络结构差别不大(Figure 16)。主要的改动体现在ZF Net中第一个卷积层使用了较小的卷积核并且将卷积步幅减少为原来的一半,这种改动保留了前两层中更多的图片特征信息。ZF Net最后的表现胜于AlexNet,在错误率上下降了1.7个百分点。另外,通过ZF Net作者们提出了一种可视化卷积层特征的方法。
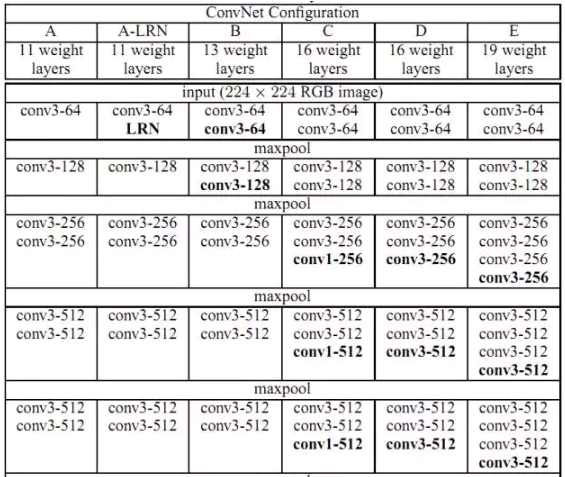
VGG Net:
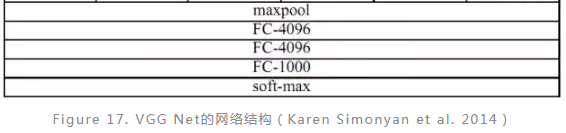
VGG Net是ILSVRC2014比赛中表现非常突出的卷积神经网络模型,其特点就是小卷积核,更深的卷积层次。该网络总共有19层,16个卷积层,3个卷积层,所有卷积核的大小均为3,多个卷积层叠加再插入池化层(Figure 17; E)。相比于ZF Net,该网络分类错误率下降了9%,分类效果显著提升。VGG Net的出现具有重要意义,它为人们提供了一个高效设计和利用CNN的方向,即层次更简单更深更有利于深层次特征的挖掘。
GooLeNet:
GooLeNet也是ILSVRC2014比赛中出现的卷积神经网络模型,该模型在此次比赛取得最佳成绩。GooLeNet的层次比VGG Net更深,总共有22层,其中21个卷积层,1个softmax输出层(Figure 18)。值得注意的是,该网络中应用了多个(9个)Inception(network in network)模块,也就是该网络并非是层与层之间按顺序依次叠加的,而是有很多并联的连接,并且模型的最后也没有应用全连接层。Inception模块的使用使得更多的特征信息被收集,去掉了全连接层减少了大量的参数,一定程度上降低了过拟合的可能。GooLeNet最终的分类结果相比于VGG Net提高了0.6%。GooLeNet的意义在于它提供了一种新的层间并联连接方式,这对以后CNN网络结构的设计具有非常大的启发作用。

ResNet:
ResNet是ILSVRC2015比赛中的冠军模型,是由微软亚洲研究院的研究人员提出的,该网络深达152层,151个卷积层,1个softmax输出层,每隔两层加入残差(Figure 19)。该网络模型将分类错误率降低至3.6%,其意义在于提出了一种新的网络结构,即残差神经网络。残差神经网络的提出一定程度上解决了深度网络无法训练的问题,为将来的应用提供非常好的改进方向。

深度学习的应用
计算机视觉:
计算机视觉是深度学习应用最为火热的领域之一,前面例举的几个网络结构都是应用在计算机视觉领域的图片分类问题上的,解决这类问题一般都会选择CNN模型。然而,对于计算机视觉领域有很多其他方面的问题,单纯应用CNN模型效果往往并不佳,例如图像标注、图像生成等问题,还需要进一步设计针对特定类型问题的模型。
目前,计算机视觉领域前沿研究最为火热的问题主要有:
- 图像分类,将不同类型的图像分开,类似于ILSVRC比赛的任务;
- 图像检测,把图像中不同的物体用框框出来;
- 图像分割,把图像中不同的物体边界描绘出来;
- 图像标注,也就是看图说话,把对应的图像用文字描述出来;
- 图像生成,就是根据文字描述生成图像;
- 视频预测,推测下时间图像中物体将会如何移动。
语音识别:
语音识别的目的就是将声音信息转化成文字,这一任务是人机交互的基础。对于这一任务,传统的解决方法一般是依赖序列模型来对语音序列建模,例如隐马尔可夫模型、高斯混合模型等,这些传统的方法单词识别的错误率较高。语音识别的过程一般涉及语音特征提取和声学建模两个方面,研究者发现利用CNN来提取语音特征可以大幅降低(6%-10%)单词识别错误率(Ossama Abdel-Hamid et al. 2014),而利用CNN进行声学建模同样具有更强的适应能力。随后,研究者们发现更深的卷积神经网络具有更好的表现,同时在解码搜索阶段将CNN、RNN以及LSTM联合起来使用会进一步提高语音识别的准确率。目前,IBM沃森研究中心报道称将ResNet与多个LSTM结合起来会使得语音识别的单词错误率降低至5.5%。实际上,苹果公司的Siri、微软的Cortana以及科大讯飞的语音识别技术都采用了最新的技术。
自然语言处理:
自然语言处理涵盖多种具体的应用,主要包括:
- 词性标注,给定句子文本,标注出句子每个词的词性;
- 句法分析,分析句子文本的语法;
- 文本分类,把内容想接近或者主题相关的文本归为相同的类别;
- 自动问答,人机交互的一种,人提供问题,机器反馈答案;
- 机器翻译,不同语言之间相互转译;
- 自动摘要,给定一个文档,自动生成该文章的内容梗概,即摘要。
目前,深度学习网络已经被广泛应用在以上任务中,早在2014年Nal Kalchbrenner等人用一种动态卷积神经网络来对语句建模(Nal Kalchbrenner et al. 2014),Baotian Hu等人利用CNN来处理语义匹配的问题,Chenxi Zhu等人则利用双向LSTM模型来解决文本匹配问题。值得注意的是,2014年ACL的最佳论文中,Devlin等人将神经网络模型引入机器翻译过程,随后便涌现出一大批解决机器翻译问题的深度学习模型,这使得机器翻译的准确率大幅提高。
推荐系统:
推荐系统是一类根据用户的历史数据来向用户推送用户可能感兴趣的信息。深度学习在推荐系统中的应用主要包括音乐推荐、电影推荐、广告投放以及新闻推送等。例如,Balazs Hidasi等人提出了一种基于RNN的推荐系统,很好的解决了传统推荐系统只能基于短期会话做推荐的问题;2014年Google利用类似MLP的网络实现了音乐语音的排名,取得了很不错的效果;Spotify利用一种典型的CNN模型进行音乐推荐。
深度学习延伸
深度学习的快速发展,不仅使得其在很多实际应用中脱颖而出,而且还带动了很多利用深度学习很容易实现的应用或者机器学习模式的发展。深度学习在人工智能领域的影响是大家公认的,但是单纯的只靠深度学习是无法让人工智能快速发展下去的。因此,新的机器学习方式和网络结构被提出,本节着重介绍几种最近非常流行的学习方式。
迁移学习:
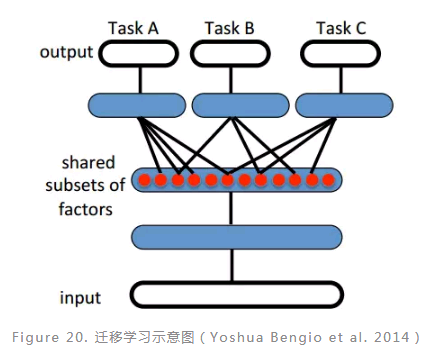
迁移学习(transfer learning)是指利用已经训练好模型的参数来帮助训练需要训练的模型。当深度学习网络比较深的时候,训练模型就会相对很复杂耗时,通过迁移学习就可以利用之前别人已经训练好的深度网络的参数来指导自己模型的训练,这样可以提高大网络训练的效率。
如图(Figure 20)所示,Task A, B, C 是三个不同的任务,但是它们的数据存在一定的相关性,因此它们之间可以共用网络前面的几层,也就是说在任务A中训练好的前面几层网络的参数可以指导B和C任务的训练。迁移学习典型例子就是谷歌公司DeepMind做的一篇文章(Andrei A. Rusu et al. 2016),文章中训练网络模型来玩三个游戏,Pong, Labyrinth 和Atari,然后利用其中一个游戏训练好的网络来玩另外两个游戏,发现结果表现很好。目前,基于深度学习的迁移学习应用已经非常广泛,例如,利用基于RBM和CNN混合模型的迁移学习框架来对图像进行分类,这种方法在Pascal VOC2007和Caltech101数据集上取得了较高的分类准确率。
强化学习:
强化学习(reinforcement learning)是机器学习的一个重要分支,主要思想是目标随着环境的改变而行动,保证最终最大化预期利益。一个强化学习模型一般包括环境、对象、动作和反馈几个基本组件,强化学习模型适合用于控制物理系统(例如无人机)、与用户交互(例如优化用户体验)、解决逻辑问题、学习序列性算法以及玩游戏等,最典型的强化学习的例子就是DeepMind开发的AlphaGo,它通过自己与自己不断地的对弈的方式来强化自己的落子准确性。另外,还有一种将强化学习和深度学习结合起来的学习框架DQN,在自然语言处理中已经应用得比较多,例如利用DQN学习对话策略、信息检索等。
对抗生成网络:
对抗生成网络(generative adversarial network, GAN)是2014年由Ian Goodfellow等人首次提出的机器学习模型,其主要思想就是有G和D两个模型,G负责学习产生数据的分布,D负责判别数据是否来自真实的分布,G的目标就是尽量生成可以瞒过D的数据,而D的目标是竭力将G生成的数据判别出来,这个对抗过程经过不断地迭代训练最终就会得到数据的生成模型G。GAN在最近两年被研究得非常火热,目前已经有各种各样变种出现,例如基于CNN的DCGAN、基于LSTM的GAN(Fang Zhao et al. 2016)、基于autoencoder的GAN(Alireza Makhzani et al. 2015)以及基于RNN的C-RNN-GAN(Olof Mogren et al. 2016)等等。这些不同变种的GAN模型已经被广泛应用在各个领域,例如图像修复、超级分辨率、去遮挡、语义分析、物体检测以及视频预测等。
学习资源
在文章的最后,我们列出一些深度学习相关的学习资源,希望对读者有帮助。
github资料:
- 深度学习相关资源,包含论文、模型、书、课程等等 https://github.com/endymecy/awesome-deeplearning-resources
- 跟对抗网络模型相关的papers: https://github.com/zhangqianhui/AdversarialNetsPapers
- Ian Goodfellow等编著的Deep learning书籍: https://github.com/HFTrader/DeepLearningBook
- LISA实验室提供的深度学习教程:
https://github.com/lisa-lab/DeepLearningTutorials
- Udacity深度学习课程的代码:
https://github.com/udacity/deep-learning
- 另一个深度学习资源库:
https://github.com/chasingbob/deep-learning-resources
- 还有一个awesome深度学习资源库,也非常全面: https://github.com/ChristosChristofidis/awesome-deep-learning
- 非常全面的公开数据集:
https://github.com/XuanHeIIIS/awesome-public-datasets
在线课程:
- 斯坦福李飞飞CS231n:
http://cs231n.github.io
- 斯坦福Richard Socher关于NLP的课程CS224d:
http://cs224d.stanford.edu/
- 伯克利Sergey Levine等教授的深度强化学习课程CS294:
http://rll.berkeley.edu/deeprlcourse/
- 牛津大学Nando de Freitas的机器学习课程:
https://www.cs.ox.ac.uk/people/nando.defreitas/machinelearning/
- LeCun的深度学习课程:
http://cilvr.cs.nyu.edu/doku.php?id=courses:deeplearning2014:start
- Hinton的神经网络课程:
https://www.coursera.org/learn/neural-networks
- 神经网络的有一个教学视频:
https://www.youtube.com/playlist?list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH
会议/期刊:
- 会议:ICLR, NIPS, ICML, CVPR, ICCV, ECCV, ACL
- 期刊:JMLR, MLJ, Neural Computation, JAIR, Artificial Intelligence
本文主要参考资料:
[1]. Ian Goodfellow et al. Deep learning. 2016
[2]. Yoshua Bengio et al. Representation Learning: A Review and New Perspectives. 2014
[3]. Yann LeCun et al. Gradient-based learning applied to document recognition. 1998
[4]. Alex Krizhevsky et al. ImageNet Classification with Deep Convolutional Neural Networks. 2012
[5]. Matthew D Zeiler et al. Visualizing and Understanding Convolutional Networks. 2013
[6]. Nitish Srivastava et al. Dropout: A Simple Way to Prevent Neural Networks from overfitting. 2014
[7]. Sergey Ioffe et al. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. 2015
[8]. 侯一民,周慧琼,王政一. 深度学习在语音识别中的研究进展综述。2016
[9]. 刘树杰,董力,张家俊等. 深度学习在自然语言处理中的应用。2015
[10]. Understanding LSTM Networks. colah’s blog



评论0