任志强说过..房价上涨是因为供给不足,供给不足根本在土地制度,城市土地就是稀缺资源
现在房租上涨,除了房屋本身供给问题外,长租供应方囤房加剧了这种上涨趋势,都想做这个行业老大,高出市场价格去收房,能不涨吗?
昨天还幻想海边别墅的年轻人,今天可能开始对房租绝望了。
8月初,有网友在“水木论坛”发帖控诉长租公寓加价抢房引起关注。据说,一名业主打算出租自己位于天通苑的三居室,预期租金7500元/月,结果被二方中介互相抬价,硬生生抬到了10800。
过去一个月,全国热点城市的房租如脱缰野马。一线的房租同比涨了近20%。一夜醒来,无产青年连一块立锥之地都悬了。
从2018下半年开始,租金海啸汹汹来袭,资本狂欢,官方默然,房东纠结,租客尖叫。
这不是一方的过错,而更像是一场全社会的“集体谋杀作品”。最令人不安的是,过去房地产的那套玩法和上涨逻辑,今天正在转移到房租上。
房租暴涨的不只是北京。有数据显示,7月份北京、上海、广州、深圳、天津、武汉、重庆、南京、杭州和成都十大城市租金环比均有所上涨。其中北京、上海、深圳的租金涨幅最猛,北京7月份房租同比上涨3.1%,有小区甚至涨幅超过30%。
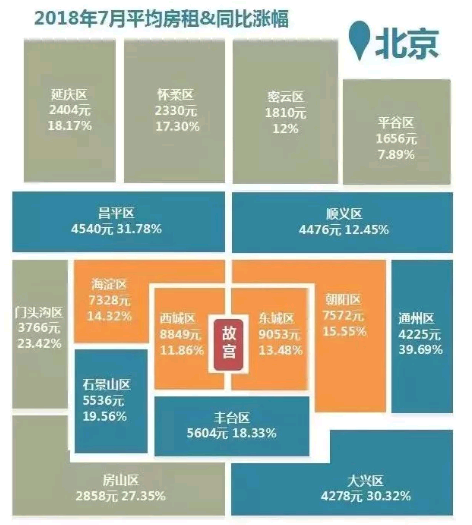
图自“21世纪经济报道”《最新房租数据出炉,你一个月要交多少钱?(附房租地图)》一文
接下来,我们将通过Python大法通过获取某网数万条北京租房数据,给大家说说真实的房租情况。
还是老规矩,老套路(是不是有股熟悉的味道),恋习Python常用的三部曲:数据获取、数据清洗预览、数据分析可视化,与你一起探究最近房租的状况。
一、数据获取
恋习Python今日就把目前市场占有率最高的房屋中介公司为目标,来获取北京、上海两大城市的租房信息。
整体思路是:
先爬取每个区域的url和名称,跟主url拼接成一个完整的url,循环url列表,依次爬取每个区域的租房信息。
在爬每个区域的租房信息时,找到最大的页码,遍历页码,依次爬取每一页的二手房信息。
post代码之前简单讲一下这里用到的几个爬虫Python包:
requests: 就是用来请求对链家网进行访问的包
lxml: 解析网页,用xpath表达式与正则表达式一起来获取网页信息,相比bs4速度更快
二、数据清洗预览
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | import requests import time import re from lxml import etree # 获取某市区域的所有链接 def get_areas(url): print('start grabing areas') headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'} resposne = requests.get(url, headers=headers) content = etree.HTML(resposne.text) areas = content.xpath("//dd[@data-index = '0']//div[@class='option-list']/a/text()") areas_link = content.xpath("//dd[@data-index = '0']//div[@class='option-list']/a/@href") for i in range(1,len(areas)): area = areas[i] area_link = areas_link[i] link = 'https://bj.lianjia.com' + area_link print("开始抓取页面") get_pages(area, link) #通过获取某一区域的页数,来拼接某一页的链接 def get_pages(area,area_link): headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'} resposne = requests.get(area_link, headers=headers) pages = int(re.findall("page-data=\'{"totalPage":(\d+),"curPage"", resposne.text)[0]) print("这个区域有" + str(pages) + "页") for page in range(1,pages+1): url = 'https://bj.lianjia.com/zufang/dongcheng/pg' + str(page) print("开始抓取" + str(page) +"的信息") get_house_info(area,url) #获取某一区域某一页的详细房租信息 def get_house_info(area, url): headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'} time.sleep(2) try: resposne = requests.get(url, headers=headers) content = etree.HTML(resposne.text) info=[] for i in range(30): title = content.xpath("//div[@class='where']/a/span/text()")[i] room_type = content.xpath("//div[@class='where']/span[1]/span/text()")[i] square = re.findall("(\d+)",content.xpath("//div[@class='where']/span[2]/text()")[i])[0] position = content.xpath("//div[@class='where']/span[3]/text()")[i].replace(" ", "") try: detail_place = re.findall("([\u4E00-\u9FA5]+)租房", content.xpath("//div[@class='other']/div/a/text()")[i])[0] except Exception as e: detail_place = "" floor =re.findall("([\u4E00-\u9FA5]+)\(", content.xpath("//div[@class='other']/div/text()[1]")[i])[0] total_floor = re.findall("(\d+)",content.xpath("//div[@class='other']/div/text()[1]")[i])[0] try: house_year = re.findall("(\d+)",content.xpath("//div[@class='other']/div/text()[2]")[i])[0] except Exception as e: house_year = "" price = content.xpath("//div[@class='col-3']/div/span/text()")[i] with open('链家北京租房.txt','a',encoding='utf-8') as f: f.write(area + ',' + title + ',' + room_type + ',' + square + ',' +position+ ','+ detail_place+','+floor+','+total_floor+','+price+','+house_year+'\n') print('writing work has done!continue the next page') except Exception as e: print( 'ooops! connecting error, retrying.....') time.sleep(20) return get_house_info(area, url) def main(): print('start!') url = 'https://bj.lianjia.com/zufang' get_areas(url) if __name__ == '__main__': main() |
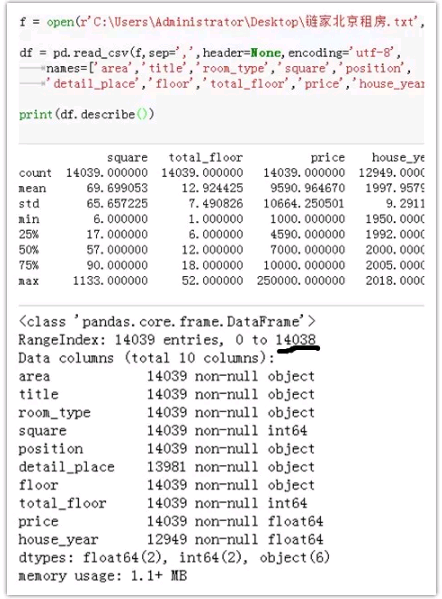
数据共14038条,10个维度,由上图可看出北京房源均价为9590元/月,中位数为7000。一半的房源价格在7000以下,所有房源的价格区间为[1000,250000],价格极差过大。
三、数据分析可视化
1. 四维度-北京房租均价
接下来,恋习Python将北京各区域、各路段、各楼盘房屋数量、均价分布放在同一张图上,更直观地来看待房租
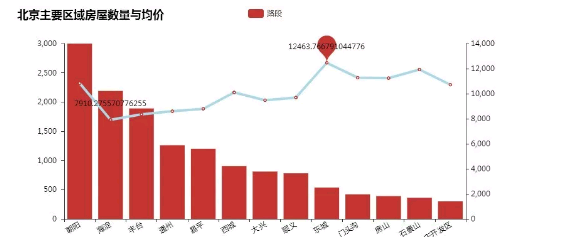
从图中可看出,最近,北京市各区域的房租均在6000元/月以上,其中最高区域为东城,均价达12463元/月。不过,由于房源信息过多过杂,房屋位置、面积、楼层、朝向等对价格均有较大影响,因此,价格这个维度需要进一步分析。
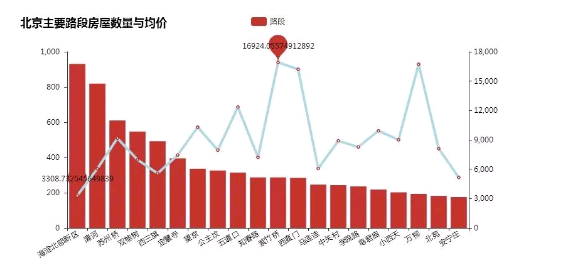
由上图可得,各路段的均价基本都在6000以上,其中海淀北部新区的房源数最多,但均价最低,为3308元/月,这或许与海淀北部生态科技新区作为高新技术产业的承载区、原始创新策源地的研发基地,以及科技园集聚区,目前已入驻华为、联想、百度、腾讯、IBM、Oracle等近2000家国内外知名的科技创新型企业有关。另一方面,海淀紫竹桥的房价竟一起冲天,其附近以博物馆、体育场馆为特色,交通便利,配套设施完善,均价较高也是情理之中。
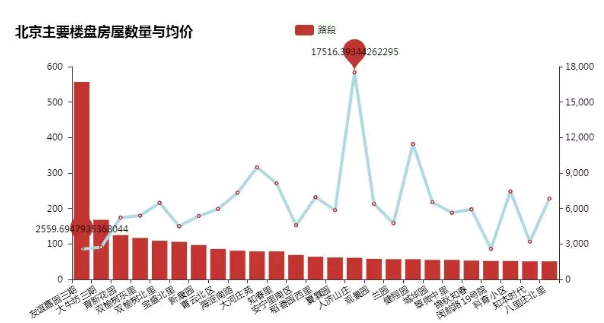
可以看出,不同楼盘的均价浮动很大,但都在6000/月以上。最高的甚至达到17516/月。由于每个楼盘户型差别较大,地理位置也较为分散,因此均价波动很大。每个楼盘具体情况还需具体分析。
附详情代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | #北京路段_房屋均价分布图 detail_place = df.groupby(['detail_place']) house_com = detail_place['price'].agg(['mean','count']) house_com.reset_index(inplace=True) detail_place_main = house_com.sort_values('count',ascending=False)[0:20] attr = detail_place_main['detail_place'] v1 = detail_place_main['count'] v2 = detail_place_main['mean'] line = Line("北京主要路段房租均价") line.add("路段",attr,v2,is_stack=True,xaxis_rotate=30,yaxix_min=4.2, mark_point=['min','max'],xaxis_interval=0,line_color='lightblue', line_width=4,mark_point_textcolor='black',mark_point_color='lightblue', is_splitline_show=False) bar = Bar("北京主要路段房屋数量") bar.add("路段",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2, xaxis_interval=0,is_splitline_show=False) overlap = Overlap() overlap.add(bar) overlap.add(line,yaxis_index=1,is_add_yaxis=True) overlap.render('北京路段_房屋均价分布图.html') |
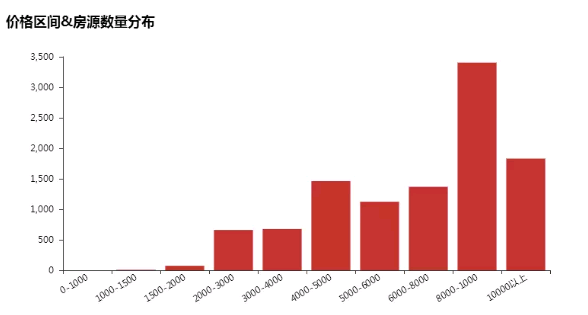
由上图可以看出,均价在8000-10000之间的房屋数量最多,同时1500-2000这个价位之间房屋数少的可怜。
据北京市统计局的数据,2017年全市居民月人均可支配收入为4769元。另据58同城和赶集网发布的报告,2017年北京人均月租金为2795元。
北京租房者的房租收入比,惊人地接近60%。很多人一半的收入,都花在了租房上,人生就这样被锁定在贫困线上。
统计数据也表明,北京租房人群收入整体偏低。47%的租房人,年薪在10万以下。在北京,能够负担得起每月5000元左右房租的群体,就算得上是中高收入人群。就这样,第一批90后扛过了离婚、秃头、出家和生育,终于还是倒在了房租面前。
附详情代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #房源价格区间分布图 price_info = df[['area', 'price']] #对价格分区 bins = [0,1000,1500,2000,2500,3000,4000,5000,6000,8000,10000] level = ['0-1000','1000-1500', '1500-2000', '2000-3000', '3000-4000', '4000-5000', '5000-6000', '6000-8000', '8000-1000','10000以上'] price_stage = pd.cut(price_info['price'], bins = bins,labels = level).value_counts().sort_index() attr = price_stage.index v1 = price_stage.values bar = Bar("价格区间&房源数量分布") bar.add("",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2, xaxis_interval=0,is_splitline_show=False) overlap = Overlap() overlap.add(bar) overlap.render('价格区间&房源数量分布.html') |
2. 面积&租金分布呈阶梯性
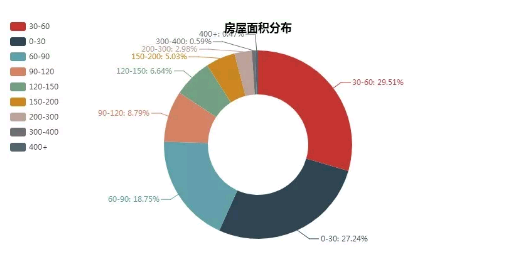
上图可以看出,80%的房源面积集中在0-90平方米之间,也符合租客单租与合租情况,大面积的房屋很少。
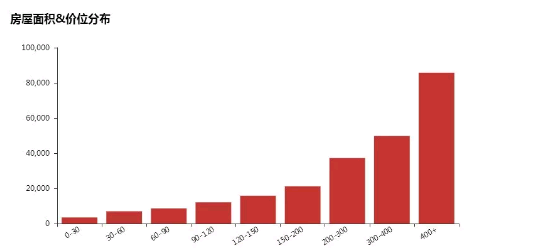
面积&租金分布呈阶梯性,比较符合常理。租房主力军就是上班族了,一般对房子面积要求较低,基本集中在30平。
附详情代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | #房屋面积分布 bins =[0,30,60,90,120,150,200,300,400,700] level = ['0-30', '30-60', '60-90', '90-120', '120-150', '150-200', '200-300','300-400','400+'] df['square_level'] = pd.cut(df['square'],bins = bins,labels = level) df_digit= df[['area', 'room_type', 'square', 'position', 'total_floor', 'floor', 'house_year', 'price', 'square_level']] s = df_digit['square_level'].value_counts() attr = s.index v1 = s.values pie = Pie("房屋面积分布",title_pos='center') pie.add( "", attr, v1, radius=[40, 75], label_text_color=None, is_label_show=True, legend_orient="vertical", legend_pos="left", ) overlap = Overlap() overlap.add(pie) overlap.render('房屋面积分布.html') #房屋面积&价位分布 bins =[0,30,60,90,120,150,200,300,400,700] level = ['0-30', '30-60', '60-90', '90-120', '120-150', '150-200', '200-300','300-400','400+'] df['square_level'] = pd.cut(df['square'],bins = bins,labels = level) df_digit= df[['area', 'room_type', 'square', 'position', 'total_floor', 'floor', 'house_year', 'price', 'square_level']] square = df_digit[['square_level','price']] prices = square.groupby('square_level').mean().reset_index() amount = square.groupby('square_level').count().reset_index() attr = prices['square_level'] v1 = prices['price'] pie = Bar("房屋面积&价位分布布") pie.add("", attr, v1, is_label_show=True) pie.render() bar = Bar("房屋面积&价位分布") bar.add("",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2, xaxis_interval=0,is_splitline_show=False) overlap = Overlap() overlap.add(bar) overlap.render('房屋面积&价位分布.html') |
3. 大多数房屋年龄在10年以上
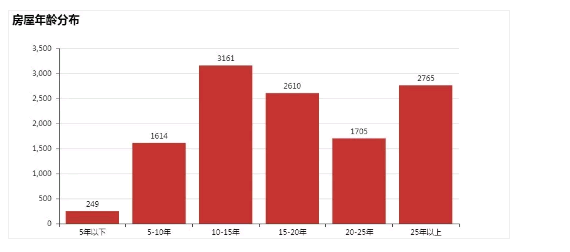
由上图看出,房屋年龄大多集中在10-20年、25年以上,而5年以下的不到2%;不过,别看这些都是老房子,最近房租变得这么猖狂?原因其中之一就是资本圈地。

这条网贴立马点燃了大众的情绪:“好啊,原来是这些长租平台烧钱圈地,一心只想要垄断市场房源,哄抬租金,企图赚取暴利差价!”
四、后记
拿自如举例,表面上看跟中介公司没啥两样,收了各种散盘,然后集中装修、出租、管理,因为运营成本和住房质量提高,房租肯定有所上涨。
但更关键的事情在背后。自如把项目打包起来搞起了资产证券化,以租金收益权为基础资产做担保,投放到金融市场上发行国内首单租房市场消费分期类ABS,让各路资金来认购,每年给大家搞点分红。
大量资本都在赌租房这个风口,而前期谁的规模越大、资源越多,以后的定价权就越大,利润空间就越不可想象。
这次恋习Python一共从链家网上爬取14038条数据,而那就是大概一周前,8月17日北京住建委约谈了几家中介公司。最终的结果是自如、相寓和蛋壳承诺将拿出12万间房子投入市场其中,自如将拿出8万间(链家、自如、贝壳找房,他们的实际控制人是同一个人–链家老板左晖。

也就是说,平常的时候,链家网+自如一共在网上待租的也就是1万多套房子,但是一被约谈他们就一口气拿出了8万套房子增援?真正的市场只有掌握了数据的公司才最清楚,而这正是数据的价值,之前说百度 阿里已经不是互联网搜索或电商,他们现在应该叫数据公司,大数据时代只有掌握了数据的公司才能很容易赚钱,链家系目前在房源这块儿最具有发言权,依靠大量的线下业务获取到的房源信息恐怕才是最真实的.




评论0